
환경구성 및 데이터 가져오기
나의 프로젝트
기본정보 -> 프로젝트 멤버 -> 데이터 관리 -> 소스 Viewer -> 분석 IDE -> 모델학습
기본정보
Dashboard 조회(자원 현황 등)
프로젝트 멤버
프로젝트 멤버 등록 : 프로젝트 내의 데이터와 소스코들을 멤버들과 공유
데이터관리
PC Data
소스 Viewer
프로젝트 멤버별 작업공간 조회
분석 IDE
Jupyter lab 또는 AIDU ez
모델학습
GPU 기반 모델학습
AIDU
Jupyter lab
- 코딩 기반의 데이터 분석 및 AI 모델 개발
- 제공 언어 : Python, R
AIDU ez
- 코딩 없는 클릭 기반의 데이터 분석 및 AI 모델 개발
- KT 활용도가 높은 AI 분석 모델 제공

데이터 분석
AI 분석 단계(AI 적용 프로세스)
- 문제 정의
- 무엇을 하고자 하는가?
- 얻고자 하는 결과는 무엇인가?
- 데이터 수집
- 어떤 종류의 데이터가 있는가?
- 얼마나 데이터를 확보할 수 있는가?
- 데이터 분석
- 의미 있는 데이터는 무엇일까?
- 데이터의 분포와 연관관계는 어떨까?
- AI 모델링
- 어떤 항목을 활용할 것인가?
- 어떻게 학습시킬 것인가?
- AI 적용
- 모델의 성능은 어떠한가?
- 모델을 어떻게 활용할 것인가?

데이터 가공
범주형/텍스트 데이터
결측값 처리 : 수치형 데이터와 다르게 최빈값, 고정값으로만 보완
데이터 변환 : 범주형 데이터를 수치형 데이터로 변환해주는 Encoder
Regex 추출 : 정규 표현식 추출
자연어 처리 : Komoran, Hannanum을 활용한 형태소 분석 및 명사 추출
수치형 데이터
결측값 처리 : 결측 데이터를 최빈값, 평균값, 중간값, 고정값으로 보완
데이터 변환 : Transformer를 이용한 데이터 분포와 Discretizer를 활용한 연속 데이터 이산화
Scale 조정 : 데이터 Feature마다 다른 Data Scale을 통일시키기 위한 Scaler(Min-Max/Standard)
AI 모델링 & 머신러닝
수학적 모델링이란?
비즈니스 문제를 파악한 후에 이를 해결하기 위한 머신러닝(인공지능) 문제로 전환
사례실습
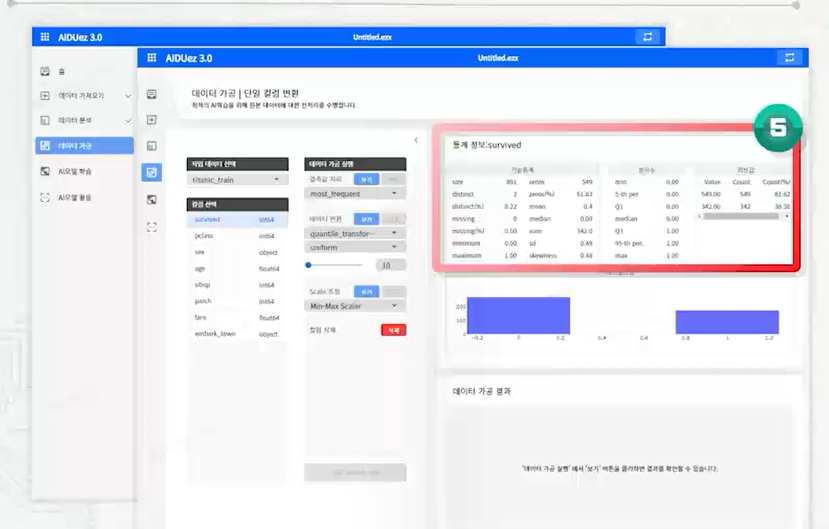
데이터 가공
distinct(%) 결측치(손실된 데이터)
결측치를 보완해야한다.
most_frequent : 최빈값(Mode) - 데이터중에서 빈도수가 가장 높은 값
median : 중위값(중앙값) - 데이터를 크기 순서대로 배열했을 때 중앙에 위치하는
mean : 평균값
constant : 내가 원하는 값 (입력하기)
AI 모델 학습 - 딥러닝 학습
Input 컬럼에서 위쪽 Output 컬럼, 아래는 제외 컬럼
데이터 유형은 category는 범주형, numerical은 수치
최솟값Minimum - 데이터 중에서 가장 작은 값
최댓값Maximum - 데이터 중에서 가장 큰 값
분산Variance - 데이터가 평균으로부터 떨어진 정도, 차이값의 제곱의 평균
표준편차Standard Deviation - 데이터가 평균으로부터 떨어진 정도, 분산의 제곱
사분위수Quartile - 모든 데이터를 순서대로 배열 시, 4등분한 지점에 있는 값
첨도Kurtosis - 데이터의 분포가 정규분포 대비 뾰족한 정도를 나타내는 값
왜도Skewness - 데이터의 분포가 정규분포 대비 비대칭한 정도를 나타내는 값
'자격증 > AICE BASIC' 카테고리의 다른 글
| AICE 합격 후기 (0) | 2024.04.04 |
|---|---|
| [이론편] AI 구현 프로세스 (0) | 2024.04.03 |
| 업무 적용 (0) | 2024.03.31 |
| AI 이해 (1) | 2024.03.29 |
| AICE Basic 자격증 소개 (0) | 2024.03.28 |